UXSTM is a configurable, stack-native ISA whose core structuring principle is a domain model. In UXSTM, functionality is partitioned into ISA domains, enabling universal cores to be configured for specific workloads by selecting the required domain blocks. The baseline domain taxonomy includes BIT, INT, WINT, FP, DP, WDP, CR, and etc. providing a systematic way to scale the architecture from minimal profiles to specialized execution targets while keeping the canonical stack (top-of-stack) execution model.
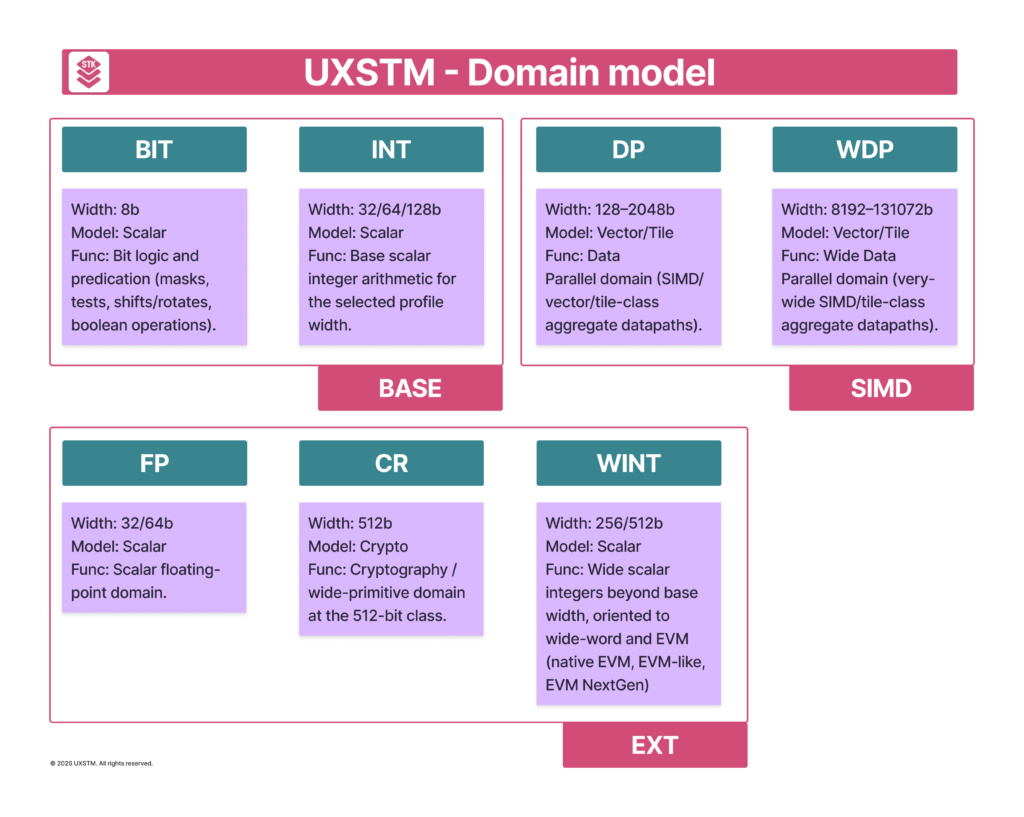
UXSTM is multi-domain. Each domain defines a typed execution surface and nominal width class:
-
BIT (8-bit) — bit logic and predication (masks, tests, shifts/rotates, boolean operations).
-
INT (32/64/128-bit) — base scalar integer arithmetic for the selected profile width.
-
WINT (256/512-bit) — wide scalar integers beyond base width, oriented to wide-word and EVM (native EVM, EVM-like, EVM NextGen).
-
FP (32/64-bit) — scalar floating-point domain.
-
DP (128–2048-bit) — Data Parallel domain (SIMD/vector/tile-class aggregate datapaths).
-
WDP (8192–131072-bit) — Wide Data Parallel domain (very-wide SIMD/tile-class aggregate datapaths).
-
CR (512-bit) — cryptography / wide-primitive domain at the 512-bit class.
A minimal UXSTM profile starts from BIT + INT, providing a compact, low-complexity core that still preserves the canonical stack (top-of-stack) execution model. From that baseline, UXSTM scales by enabling only the domains required by the target workload—adding floating-point, wide integers, crypto primitives, and data-parallel (SIMD/tile) capability as needed. In practice, this yields a family of profiles ranging from low-power embedded targets to blockchain execution engines, batch/rollup acceleration, and high-throughput AI/HPC configurations.
-
BIT + INT → minimal / low-power baseline (control, integer logic, lightweight runtimes).
-
BIT + INT + FP → MCU-class and general embedded that needs scalar FP (control + basic numeric).
-
BIT + INT + FP + WINT + CR → EVM-oriented execution (wide word + crypto primitives).
-
BIT + INT + FP + WINT + DP + CR → rollups / batching / throughput-oriented blockchain compute (wide + crypto + data-parallel for batch kernels).
-
BIT + INT + FP + DP → general-purpose / “light server” (scalar + data-parallel acceleration for common kernels).
-
BIT + INT + FP + DP + WDP + CR → high-load, scientific compute, AI/inference training pathways (parallel width scaling + crypto availability).
See Also: